|
Michael Noseworthy I am a graduate student in the Robust Robotics Group at MIT. My research focuses on robust planning under uncertainty motivated by long-horizon manipulation tasks such as assembly or rearrangement. I have interned at the NVIDIA Seattle Robotics Lab where I worked on contact-rich manipulation. Before MIT, I studied dialogue systems at McGill University's Reasoning and Learning Lab. |

|
Research |

|
FORGE: Force-Guided Exploration for Robust Contact-Rich Manipulation under Uncertainty
CORL 2024 Workshop on Learning Robotic Assembly [Best Paper]
Sim-to-real transfer of force sensing for contact-rich assembly tasks. Paper / Website |

|
Amortized Inference for Efficient Grasp Model Adaptation
ICRA 2024
Adaptively grasping objects without unknown dynamics properties (e.g., mass distribution or frictional coefficients). Paper |
|
Insights towards Sim2Real Contact-Rich Manipulation
NeurIPS 2022: Robot Learning Workshop
Training policies to solve contact-rich manipulation tasks with noisy pose estimates. Paper |
|
|
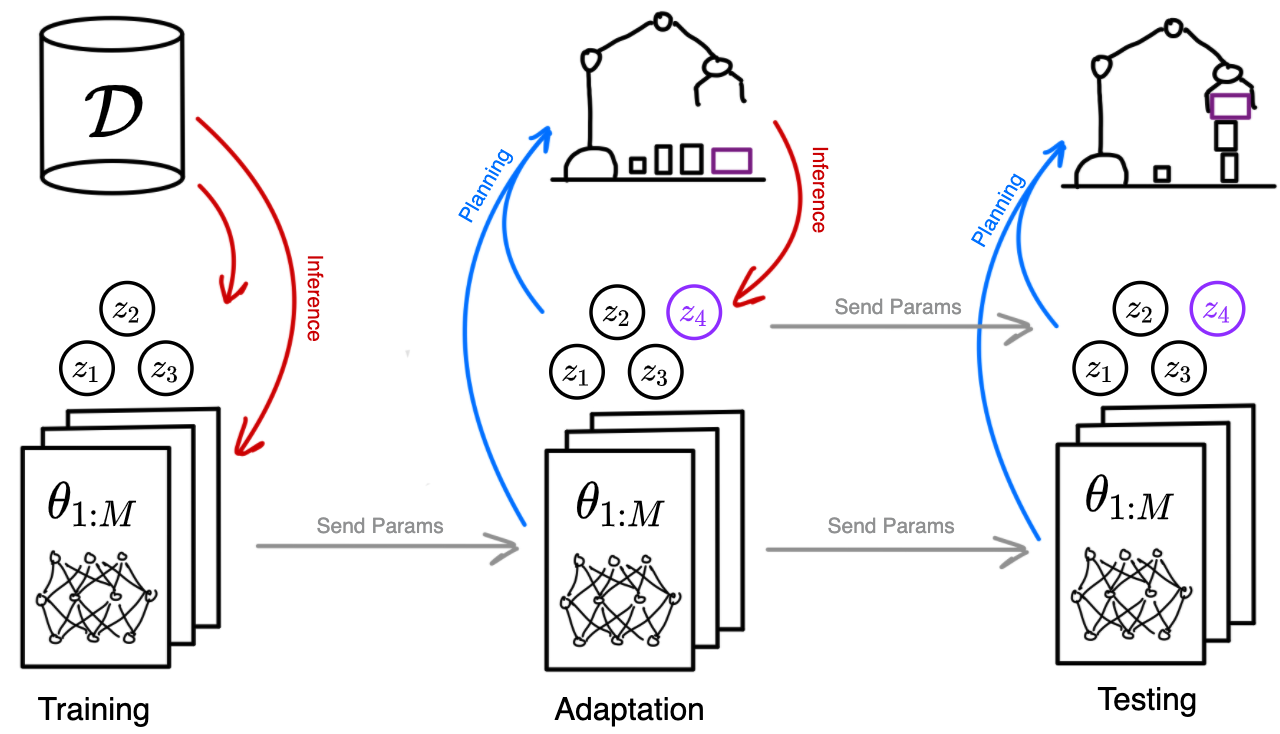
Object-Factored Models with Partially Observable State
NeurIPS 2021: Bayesian Deep Learning Workshop
Efficient adaptation for manipulating objects with non-visual parameters. Paper |
|
Active Learning of Abstract Plan Feasibility
RSS 2021
Efficient online learning of feasility models using ensembles of graph networks. Paper / Talk |
|
|
Visual Prediction of Priors for Articulated Object Interaction
ICRA 2020
Efficient manipulation of articulated objects using visual priors to infer kinematic parameters. Paper / Talk / Code / Website |
|

|
Task-Conditioned Variational Autoencoders for Learning Movement Primitives
CORL 2019
Learning interpretable movement primitives from demonstration. Paper |

|
Inferring Task Goals and Constraints using Bayesian Nonparametric Inverse Reinforcement Learning
CORL 2019
Learning from demonstration in the presence of complex constraints. Paper |

|
Leveraging Past References for Robust Language Grounding
CoNLL 2019
Natural language grounding in situated and temporally extended contexts. Paper |
|
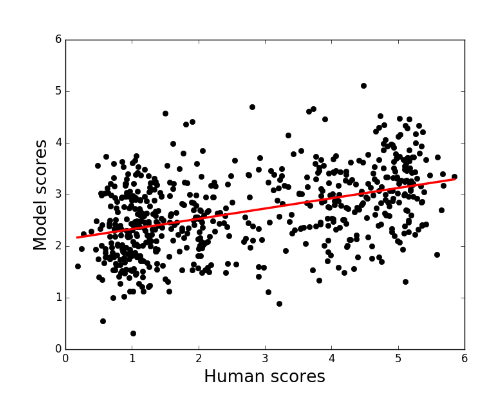
Towards an Automatic Turing Test: Learning to Evaluate Dialogue Responses
ACL 2017 [Outstanding Paper]
Automatic metric for dialogue model response evaluation. Paper / Code / Talk |
|
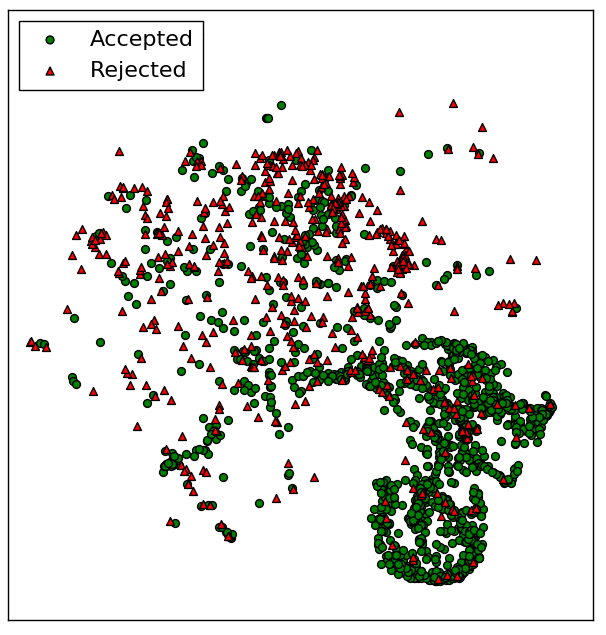
Predicting Success in Goal-Driven Human-Human Dialogues
SIGDIAL 2017
Automatic success prediction for task-driven dialogue systems. Paper |
|
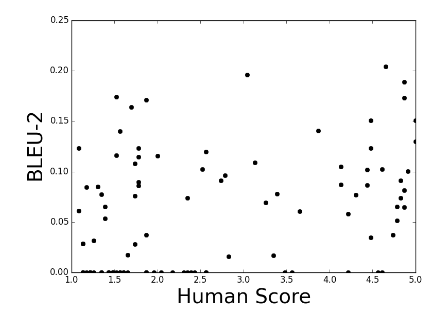
How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation
EMNLP 2017
A study of how common automatic metrics for evaluating dialogue responses correlate with human judgement. Paper / Talk |
Miscellanea |
 |
Inclusion@CoRL Organizer, CoRL 2020
Queer in AI Organizer, RSS 2021 Queer in AI Organizer, CoRL 2021 |
|
Website template from Jon Barron. |